
How does Bablic work?
Overview:
You have been provided with a snippet of JavaScript code that you will inject into the <head> section of your website. This one-time step is the only integration required, and it allows the browser to execute Bablic's translation library.
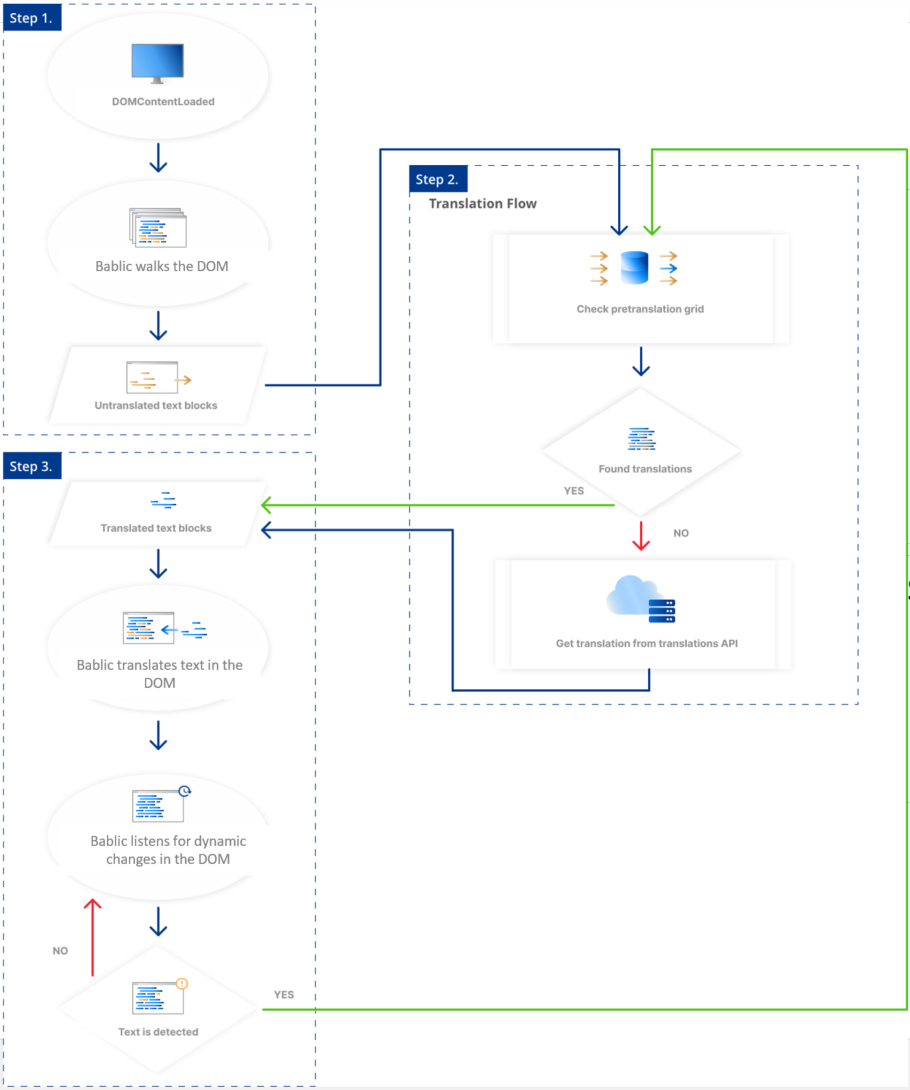
When a translated page is requested, the library collects text nodes from the page and retrieves the corresponding Machine Translations from Bablic’s cloud-based endpoints. The origin text nodes are then replaced with their localized equivalents on the page instantaneously. The translations for the page are cached in a Content Delivery Network (CDN) to optimize performance for subsequent requests for the same language.
Once the page is translated, Bablic continues listening to the DOM via a MutationObserver for any dynamic changes or interactive content that may need a translation. When a modification resulting in new text is detected, the new text is translated on the fly.
MutationObserver Support

If a browser does not support MutationObserver, it will be unable to run Bablic. You can find more information about the MutationObserver here.
Browser Mechanism
Step1
The first step is content extraction. Bablic collects content by filtering for text nodes and translatable attributes.
Step 2
Text blocks are checked against the Pretranslate array, and any missing blocks are sent to the Translation API.
Step 3
The page is updated with the localized text equivalents. Bablic continues listening to the page for any dynamic changes or interactive content and proceeds through the translation cycle again if necessary.
If you want to be more hands-on and control your translations with precision, visit our Translation Management section for more information on all the tools available to you on the Bablic platform.